
粗浅理解,文中若有错误,欢迎您的批评指正!
pnpm
pnpm 是由 npm/yarn 衍生而来,但是却解决了 npm/yarn 内部潜在的 bug,并且极大地优化了性能,扩展使用场景。下面是思维导图:
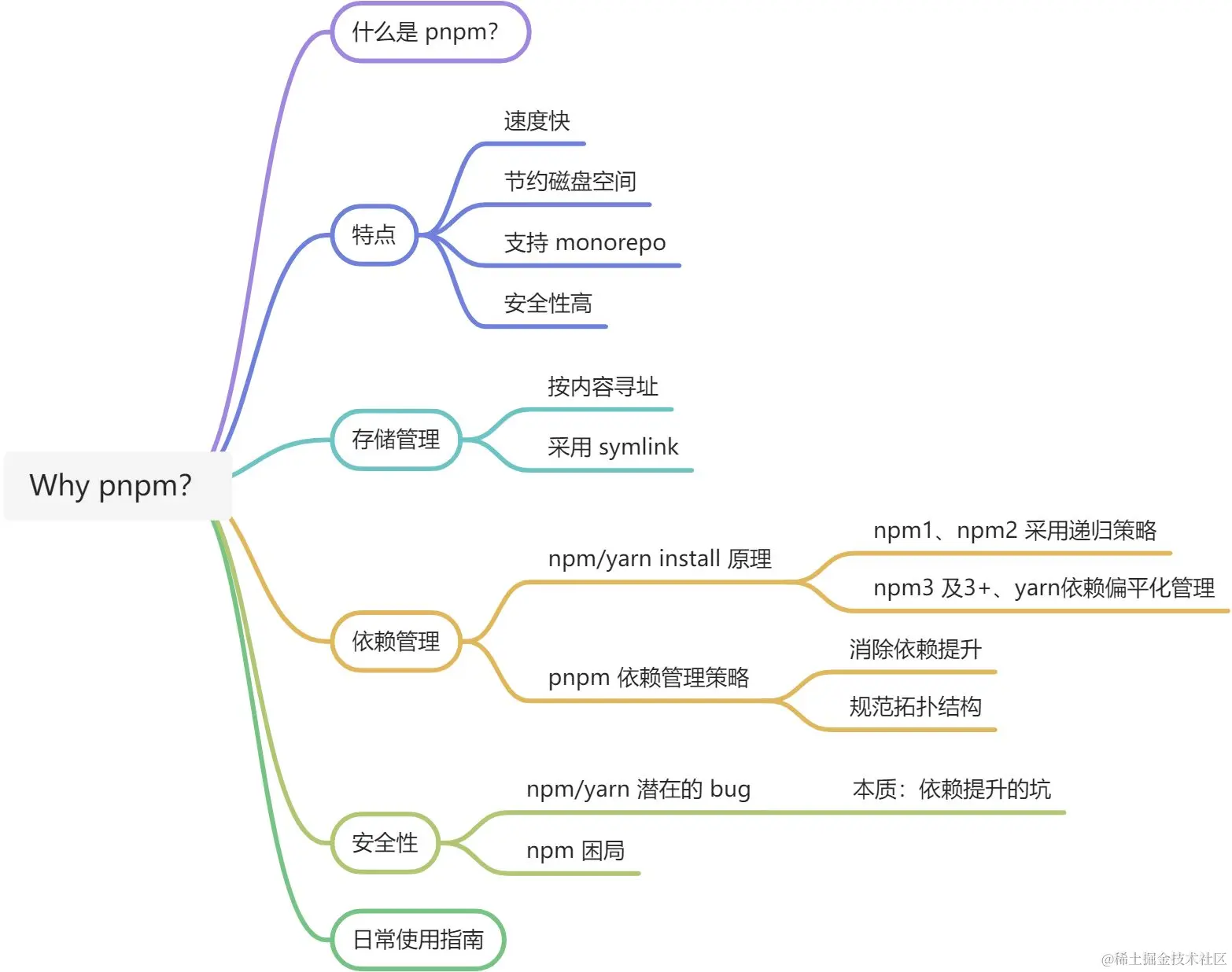
什么是 pnpm?
pnpm 的官方文档是这样说的:
Fast, disk space efficient package manager
因此,pnpm 本质上是一个包管理工具,这一点上是跟 npm/yarn 没有区别的。那么它的优势在于:
- 包安装速度极快
- 磁盘空间利用非常有效
使用
安装 pnpm
npm i -g pnpm具体使用命令与 npm 使用方法一致。
pnpm install xxx
pnpm add xxx特点
速度快
pnpm 安装包的速度究竟有多快?在绝大数场景下,pnpm 安装包的速度会比 npm/yarn 快 2-3 倍。
高效利用磁盘空间
pnpm 内部使用基于内容寻址的文件系统来存储磁盘上所有的文件,这个文件系统出色的地方在于:
- 不会重复安装同一个包,用 npm/yarn 的时候,如果有 100 个项目都依赖于 loadhash,那么 loadhash 很有可能就被安装 100 次,磁盘就有 100 个地方写入了这部分代码。但是在使用 pnpm 只会安装一次,磁盘中只有一个地方写入,后面都会使用 hardlink(硬链接)。
- 即使一个包的不同版本,pnpm 也会极大程度地复用之前版本的代码。举个例子,比如 lodash 有 100 个文件,更新版本之后多了一个文件,那么磁盘当中并不会重新写入 101 个文件,而是保留原来的 100 个文件的 hardlink,仅仅写入那一个新增的文件。
支持 monorepo
随着前端工程的日益复杂,越来越多的项目开始使用 monorepo。 之前对于多个项目的管理,我们一般都是使用多个 git 仓库,但 monorepo 的宗旨就是用一个 git 仓库来管理多个子项目,所有的子项目都存放在根目录的 packages 目录下,那么一个子项目就代表一个 package。
如果你之前没接触过 monorepo 的概念,建议仔细看看这篇文章以及开源的 monorepo 管理工具lerna,项目目录结构可以参考一下babel 仓库。
pnpm 与 npm/yarn 另外一个很大的不同就是支持了 monorepo,体现在各个子命令的功能上,比如在根目录下 pnpm add A -r, 那么所有的 package 中都会被添加 A 这个依赖,当然也支持 --filter 字段来对 package 进行过滤。
安全性高
之前使用 npm/yarn 的时候,由于 node_module 的扁平结构,如果 A 依赖 B,B 依赖于 C,那么 A 是直接可以使用 C 的,但是问题是 A 当中并没有声明 C 这个依赖,因此会出现非法访问的情况。
依赖管理相关原理
npm/yarn install 原理
主要分为两个部分,首先,执行 npm/yarn install 之后,包是如何到达项目 node_modules 当中。其次,node_modules 内部是如何管理依赖。
执行命令后,首先会构建依赖树,然后针对每个节点下的包,会经历下面四个步骤:
- 将依赖包的版本区间解析为某个具体的版本号;
- 下载对应版本依赖的 tar 包到本地离线镜像;
- 将依赖从离线镜像解压到本地缓存;
- 将依赖从缓存拷贝到当前目录的 node_modules 目录。
也就是经历 解析,下载,解压,拷贝 四个过程之后,我们所需要的包会到达项目的 node_modules 目录中。
那么,这些依赖在 node_modules 内部是什么样的目录结构呢,换句话说,项目的依赖树是什么样的呢?
在 npm1、npm2 中呈现出的是嵌套结构,比如下面这样:
node_modules
└─ foo
├─ index.js
├─ package.json
└─ node_modules
└─ bar
├─ index.js
└─ package.json接着,从 npm3 开始,包括 yarn,都着手通过 扁平依赖 的方式来解决这个问题。相信大家都有这样的体验,我明明安装个 express,为什么 node_modules 里面多了这么多东西?
node_modules
├─ foo
| ├─ index.js
| └─ package.json
└─ bar
├─ index.js
└─ package.json所有的依赖都被拍平到 node_modules 目录下,不再有很深层次的嵌套关系。这样在安装新的包时,根据 node require 机制,会不停往上级的 node_modules 当中去找,如果找到相同版本的包就不会重新安装,解决了大量包安装的问题,而且层级也不会太深。
但是存在以下问题:
- 依赖结构的不确定性
- 扁平化算法本身的复杂性很高,耗时较长。
- 项目中仍然可以非法访问没有声明过的依赖包。
其中,对于第一点不确定性的问题:
假如现在项目中依赖两个包 foo 和 bar,这两个包的依赖是怎样的?npm/yarn install 的时候,通过扁平化处理之后,究竟是这样:
还是这样:
答案是:都有可能!取决于 foo 和 bar 在
package.json中的位置,如果 bar 声明在前面,那么就是前面的结构,否则就是后面的结构。

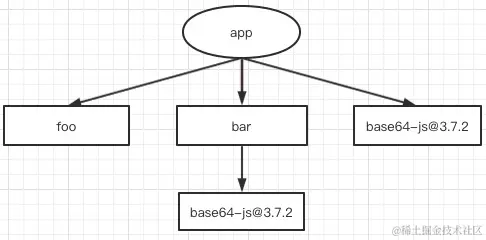
这就是为什么产生依赖结构不确定性问题,也就是 lock 文件诞生的原因,无论是和
package.json还是yarn.lock,都是为了保证 install 之后能产生确定的node\_modules 结构。
尽管如此,npm/yarn 本身还是存在扁平化算法和 package 非法访问的问题,影响性能和安全。